
LLMs.txt for AEO: Worth It or Not?
Learn when llms.txt helps AEO, where it fits, and why it supports AI visibility without replacing core SEO fundamentals for modern sites.




llms.txt has quickly become one of the most talked-about files in AI search circles. That usually happens when a tactic sits at the intersection of genuine usefulness and exaggerated expectations.
So, is it worth adding to an AEO program?
The short answer is yes, sometimes. The better answer is that llms.txt is a helper, not a shortcut. It can make high-value content easier for language models and agents to interpret, yet it does not replace technical SEO, content quality, entity clarity, or site architecture. And if your team is chasing visibility in Google Search or AI Overviews, Google has already said you do not need llms.txt or special AI markup to appear there.
That distinction matters.
What llms.txt actually is for AEO
The original proposal at llmstxt.org describes llms.txt as a markdown file placed at the root of a site, intended to help LLMs use a website at inference time. That is a very different claim from “this file improves rankings” or “this file gets you cited by ChatGPT.”
It is also not a formal web standard. The proposal is useful and increasingly visible, though it is still a proposal. Sources outside the proposal itself have made the same point. Terminalfour, for one, describes it as an emerging convention rather than an officially ratified specification.
In plain English, llms.txt is closer to a curated reading map than a search ranking signal.
After that framing, the recommended structure becomes easier to read:
- H1: a clear title for the site or section
- Blockquote summary: a short explanation of what the site offers
- Curated links: important markdown resources grouped into useful sections
- Markdown delivery: companion
.mdversions of key pages when possible
That design tells you a lot. This file is about access, clarity, and curation.
What Google says about llms.txt and AI search visibility
Google’s guidance is direct: you do not need llms.txt files or other special AI markup to appear in Google Search, including generative AI features like AI Overviews. Google also says those features rely on its core ranking and quality systems, with retrieval-augmented generation grounded in Search index results.
That means foundational SEO still carries the weight. Crawlability, indexability, page quality, helpful main content, internal linking, source clarity, and strong information architecture still set the table. If those basics are weak, adding llms.txt will not rescue performance.
This is where many AEO discussions go sideways. Teams often assume that anything with “LLM” in the name must be a direct path to inclusion in model answers. Official guidance does not support that view. A more disciplined read is that llms.txt may help some systems consume or prioritize a site’s best materials, while Google’s generative search features still depend on the same quality signals that have mattered for years.
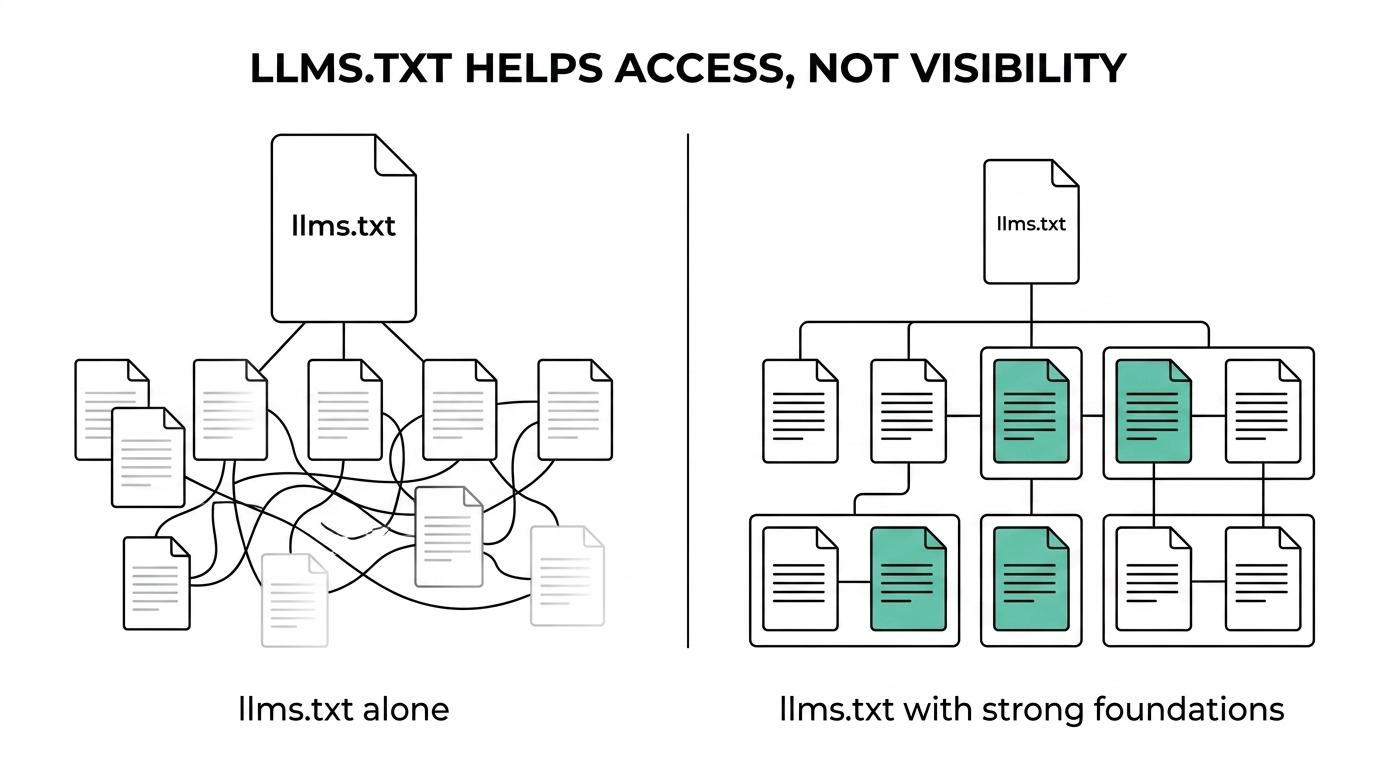
There is a second lesson here. New files and markup are often treated as if implementation alone creates eligibility. Google’s own documentation on structured data has long made the opposite point: even valid markup does not guarantee rich results. llms.txt deserves the same sober treatment.
What Cloudflare’s approach says about agent readiness
Cloudflare offers one of the most practical signals in this discussion because it has written about agent-facing documentation in operational terms, not hype. In its write-up on agent readiness, Cloudflare describes llms.txt as a plain-text file at the root of a site that gives agents a structured reading list of important content.
That framing is strong because it keeps the file in proportion. A reading list is useful. A reading list is not the library.
Cloudflare also highlights something many marketing teams miss: large documentation sets can blow past model context windows. Its answer was not “make one giant llms.txt.” It created separate files for top-level directories, removed low-value directory listing pages, and added better descriptive context to the pages it wanted agents to read.
That is a real AEO lesson. Better inputs beat bigger files.
A practical read of Cloudflare’s pattern looks like this:
- smaller, section-level files
- cleaner markdown output
- stronger page summaries
- fewer low-value URLs
- clearer documentation hierarchy
If your site has thousands of pages, that is far more useful than publishing a token llms.txt and calling the job done.
When llms.txt is worth the effort
llms.txt is most valuable when a site already has depth and needs a cleaner handoff layer for models, agents, or AI-assisted retrieval systems. Think of it as a packaging improvement for content that already deserves to be found and cited.
It is especially sensible for documentation-heavy properties, knowledge bases, developer portals, API ecosystems, research libraries, and content archives with strong topical organization. Those environments benefit from curated paths because raw crawl access alone may surface too many weak or redundant pages.
The pattern is less urgent for small brochure sites with a handful of pages. In those cases, time is often better spent on content quality, entity consistency, structured navigation, and evidence-backed copy.
Here is a simple way to assess fit:
[markdown] | Site type | llms.txt value | Why | | --- | ---: | --- | | Developer docs | High | Large content sets benefit from curated reading paths and markdown versions | | B2B SaaS help center | High | Product explainers, setup guides, and troubleshooting content are strong agent inputs | | Research or publishing archive | Medium to High | Topic clusters and summaries help models identify canonical resources | | Mid-market marketing site | Medium | Useful if content depth is strong, less useful if the site is thin | | Small service site | Low to Medium | Core SEO, trust signals, and page quality usually matter more first | | E-commerce catalog | Low to Medium | Product feed quality, taxonomy, and structured content tend to be bigger priorities | [/markdown]AEO leaders should like this table because it shifts the conversation from trend chasing to opportunity cost.
When llms.txt is not the priority
If your content is weak, duplicated, vague, or hard to crawl, llms.txt is not the next best move. The file can organize good assets. It cannot manufacture authority.
The same goes for sites with poor internal linking, sloppy canonicalization, fragmented brand entities, or thin bottom-funnel pages. If your product comparisons, use cases, documentation, and trust pages are underbuilt, that is where the upside sits.
A stronger AEO priority stack usually looks like this:
- First: fix crawl, indexation, and internal linking
- Second: publish source-worthy pages with expert depth
- Third: tighten entity consistency across site, PR, profiles, and citations
- Fourth: create markdown-friendly content access
- Fifth: add
llms.txtas a curated layer
That order is not flashy, though it is hard to argue with.
There is also a governance angle. Because llms.txt is not a formal standard, support will vary by platform and use case. Some agents may read it. Others may ignore it. Some may benefit more from the linked markdown pages than from the file itself. That uncertainty is fine as long as the implementation cost stays low and the rest of your system is already healthy.
How to implement llms.txt without wasting cycles
The best implementations are selective. They do not try to summarize the whole company, every page, every press mention, and every blog post in one place.
Start with the pages you would want a human analyst, a buyer, or an AI agent to read first. That often includes product documentation, integration pages, technical explainers, pricing context, security material, API references, migration guides, and authoritative category pages.
Then make those pages easier to consume. If you publish markdown versions, make sure they are clean. Strip unnecessary chrome. Use descriptive headings. Keep authorship, dates, definitions, and versioning clear. A bad .md output is still bad content.
A compact operating model works well:
- Audit the pages most likely to support citations or answer generation.
- Remove or de-emphasize low-value URLs that create noise.
- Build a root
llms.txtfile that links to the best resources. - Add section-level files if the site is large or documentation-heavy.
- Monitor logs, referral patterns, citations, and answer quality over time.
This is also a strong place to apply bottom-funnel thinking. If a company wants measurable business impact from AI visibility, the highest-priority materials are rarely generic thought leadership posts. They are pages that clarify product fit, implementation, risk, comparison, pricing logic, and technical proof.
What a strong llms.txt file should include
A strong file is opinionated. It should help a system identify the site’s best, most reliable resources quickly.
That usually means including concise summaries, canonical links, and grouped sections that reflect user tasks rather than internal org charts. A product buyer does not care which team owns a page. An agent does not either.
Good section choices might include onboarding, APIs, use cases, compliance, pricing context, migration, troubleshooting, and glossary content. Those categories help both humans and models.
Just as important, leave things out. Directory listings, tag archives, thin press snippets, and duplicate announcements often add noise. Cloudflare’s public guidance supports this cleaner approach, and it lines up with how modern retrieval systems handle finite context windows.
What to measure after publishing llms.txt
This is where AEO discipline separates useful experiments from vanity work.
Do not measure success by the existence of the file. Measure whether key content becomes more visible, more referenced, and more likely to support qualified discovery. In many programs, the strongest signal is not raw traffic. It is better assisted discovery of the pages that convert serious buyers.
Useful metrics can include:
- citation frequency in AI-generated answers
- branded and non-branded organic visibility on core pages
- crawl behavior on linked markdown resources
- documentation page engagement
- qualified pipeline influenced by organic and AI-assisted discovery
If those numbers do not move, the file may still be fine. It may just mean the real bottleneck sits elsewhere, usually in content quality, site structure, or authority signals.
That is the right way to think about llms.txt for AEO. It can be worth it, often enough to justify the effort, though rarely as the first move and never as the whole strategy. The winning posture is simple: build pages worth citing, make them easy to retrieve, and use llms.txt as a clean guide rather than a magic switch.


